
I Told You How to Build a Knowledge Base. Then I Rebuilt Mine.
The Setup I Shared 3 Months Ago Stopped Working. Here's What Replaced It.


Last month, I listened to a podcast that changed how I think about a project I’m working on. (I’m talking in a very specific, “I know exactly where this applies” way.)
And my first thought when I heard it wasn’t to save it. It was: where does this go so it actually shows up when I need it?
I opened my knowledge folder to figure that out.
What I found was the same setup I’d built three months ago and written a three-part series telling you to build too: 330 frameworks in one alphabetical file, 130 benchmarks in another, a routing index that hadn’t been updated in two months, and a CLAUDE.md instruction that said “load both files at the start of every session.”
Nothing had changed since the day I built it.
None of it had been touched, tested, or questioned since March.
I’d solved the graveyard problem for my Notion archive. Then I’d built a new one out of the fix.
The 415-Line File
Let me show you what “load both files at the start of every session” actually looked like.

My FRAMEWORKS.md was 415 lines long. Alphabetized. Every named mental model, principle, or methodology I’d ever extracted from a book summary, listed one line at a time.
First Principles Thinking sat twelve lines above the Focusing Illusion. The AIDA copywriting formula sat next to the Ackerman Bargaining Model. Bulking Macronutrient Ratios (from a bodybuilding book I’d summarized in 2022) sat right there alongside them.
Every session carried all of it. Writing a Dreem marketing email? Claude had my bodybuilding protein ratios in context. Journaling about a personal decision? Claude had loaded 40 copywriting frameworks I didn’t need. The instruction said “load everything,” so it loaded everything.
BENCHMARKS.md was 130 statistics organized by domain, loaded alongside the frameworks whether or not the session called for them. Ogilvy’s headline stats in one file, the copywriting principles they belonged with in another.
And then there was TOPIC-INDEX.md, a routing layer I’d built to point Claude at the right book summaries for a given topic. There were 26 categories, but I hadn’t updated it since March 29th.
I’d read and summarized new books since then, but the index didn’t know they existed. The setup wasn’t broken. It was working exactly as designed. The problem was the assumption underneath it:
A Knowledge Base Is Something You Maintain
That was the assumption I’d never examined. I’d built a system that required regular attention, then walked away from it for two months.
Under the old system, that podcast would’ve gone into FRAMEWORKS.md as two more lines in the alphabetical list. If it surfaced at all, it would’ve surfaced in every session, alongside everything else.
I started over with the layer on top of the book summaries: the extraction files that were supposed to make the knowledge usable. The goal was simple:
Reference files that capture the ideas a decade-plus practitioner would actually reach for, organized so Claude loads the right domain depending on what I’m doing.
I replaced FRAMEWORKS.md and BENCHMARKS.md with ten pillar files, one per domain: Copywriting & Persuasion, Decision-Making, Marketing & Growth, Writing Craft, Productivity & Systems, Habits & Behavior Change, Mindset & Resilience, Personal Finance, Philosophy & Purpose, Leadership & Business.
Each one is a wiki-style reference with prose entries organized by cluster, not a list of one-liners. Frameworks and benchmarks live together (Ogilvy’s headline stats next to the copywriting principles they support). The total across all ten is around 430 concepts, drawn from the broader canon of each field, not just the books I happened to own.
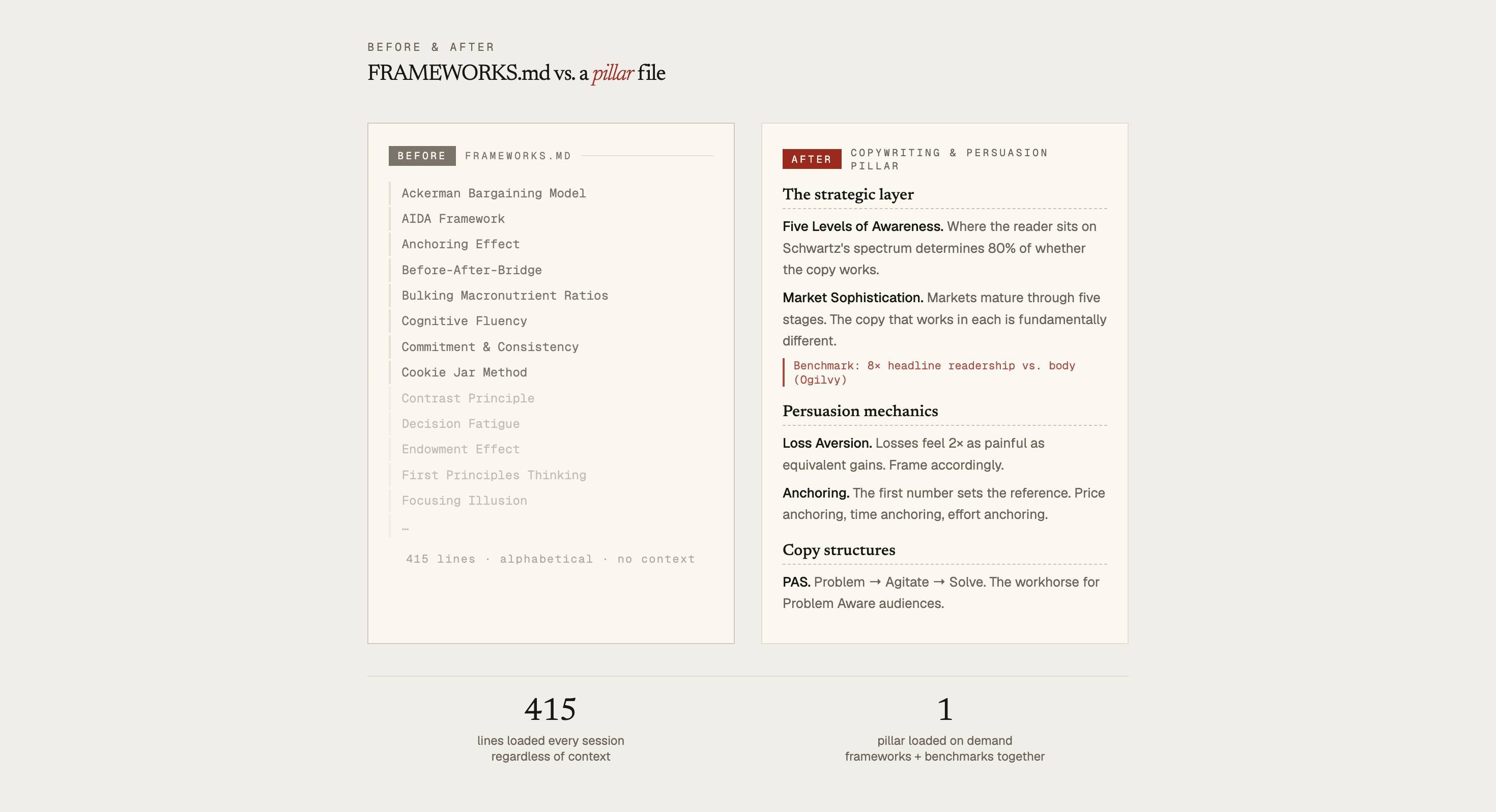
The curation filter is what separates this from a dump. If a concept wouldn’t survive outside the book it came from, it stays in the book summary.
First Principles Thinking, Loss Aversion, the WRAP Process: in. Bulking Macronutrient Ratios, the Ackerman Bargaining Model: out.
One File, Loaded on Demand
The routing changed. The CLAUDE.md no longer says “load both files every session.” It says “load the relevant pillar when work calls for it.”

For instance, last week, I was writing copy for Dreem lifecycle emails and needed to make sure I was hitting the fundamentals: subject line mechanics, CTA placement, the sequencing principles that separate a drip campaign from spam.
Under the old system, Claude would’ve loaded 415 lines of everything—bodybuilding macros, decision-making biases, the full alphabetical run. Instead, it loaded the Marketing & Growth pillar.
One file sharing the concepts I actually needed, organized by cluster, with the benchmarks sitting next to the principles they support. One file, loaded on demand.
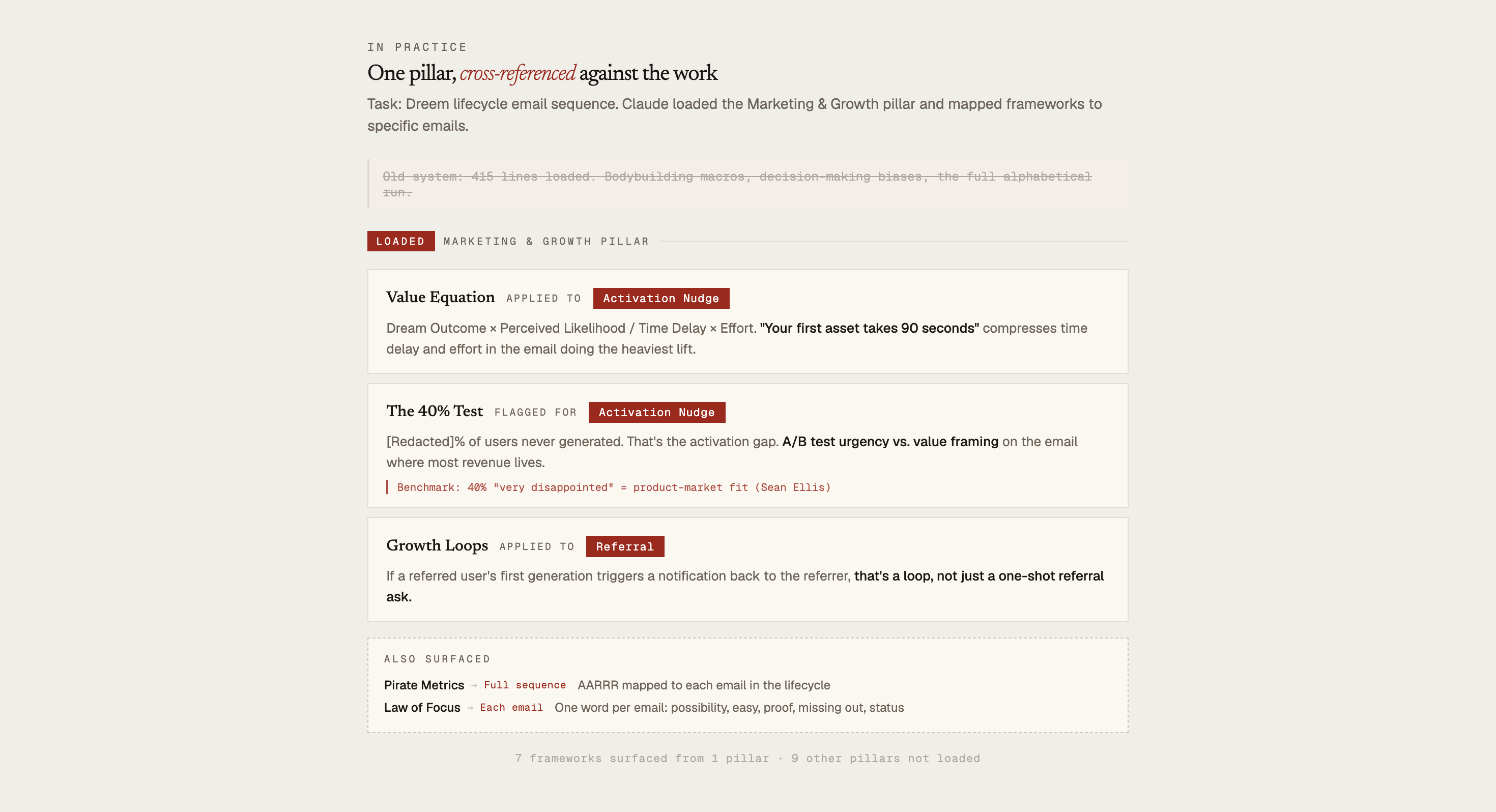
The context window carries what the session needs. That podcast from last month? It went into the Marketing & Growth pillar. Two concepts earned their spot. The rest stayed in the archive.
My knowledge folder has stopped being a library I visit, and instead, it’s become the thing I wanted Notion to be three years ago: a place where what I’ve read shows up in the work, without me having to remember it was there.
If you enjoyed this read, the best compliment I could receive would be if you shared it with one person or restacked it.